
很多人看到我整理的 coding,第一反应都很像:
“这不就是在刷题吗?”
如果只看目录,这么理解一点都不奇怪。因为那里面确实是一道道题,从两数之和、滑动窗口、链表、二叉树,到动态规划、图论、Trie、LRU 缓存,一路排到了 107 题。
但把这件事从头到尾做完后,我最大的感受反而不是“我又刷了很多题”,而是终于更清楚地看见了一件事:
真正拉开编程能力差距的,从来不是题量本身,而是你有没有借这些题,把一套稳定的问题解决能力练出来。
也就是说,题目只是表面。真正被训练的,是底层的方法感、判断力和表达力。
让我真正警惕的,不是不会做题,而是会了也留不住
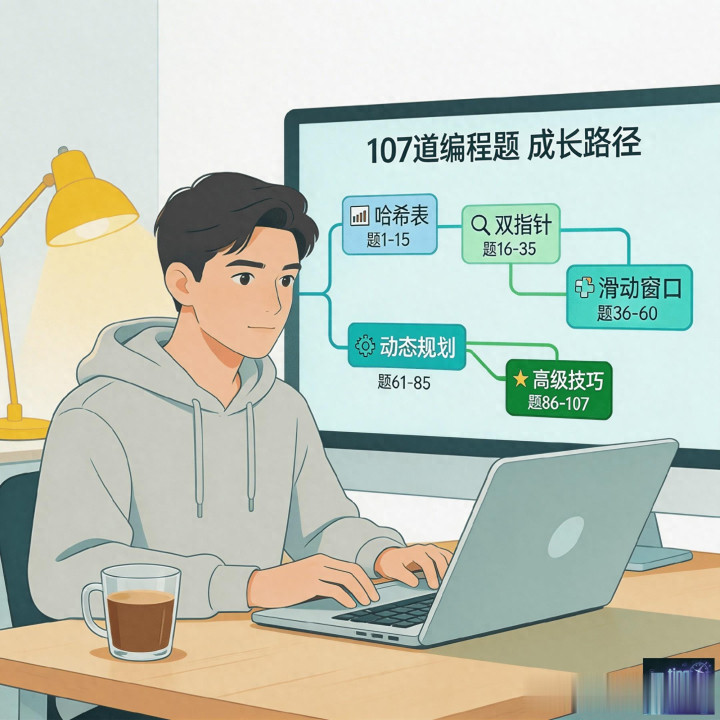
107道编程题模块化成长路径思维导图
我一开始也走过那条很多人都熟悉的路。
找一份热门题单,每天做几道;不会就看题解;看懂了就算“过了一题”;隔几天再遇到一个变形题,还是不会。表面上看,这个过程很努力,也很有进度感,但真正让人焦虑的地方恰恰在这里:你明明刷了不少题,可一旦题目换个问法、换个约束、换个数据结构,手感就会突然掉下去。
后来我越来越确定,这种不稳定感并不是因为题刷得还不够,而是因为很多题在脑子里只是“见过”,没有真正变成“会用”。
两数之和、无重复字符的最长子串、岛屿数量、零钱兑换、LRU 缓存,很多经典题大家都刷过。可如果这些题最后只剩下“题号”和“答案”,那它们对真实代码能力的帮助其实有限。因为真实工作不会给你原题,它只会把问题换一种形态重新扔过来。
这也是我后来重新整理这套内容的原因。我想解决的已经不是“我还差几题没做”,而是“这些题到底能不能被组织成一条清晰的成长路径”。
把 107 道题放进 15 个模块后,我才第一次看见成长路径

编程模式识别雷达图,开发者指向核心模块
当题目只是零散排列的时候,它更像一个题库;当题目被组织成结构,它才开始像训练系统。
后来这 107 道题被我归到了 15 个核心模块里,包括哈希表、双指针、滑动窗口、字符串、链表、栈与队列、二叉树、二分查找、回溯、贪心、动态规划、图论、堆与优先队列、前缀树,以及一些高级技巧。
这个变化看起来只是“换了一种目录方式”,但它对学习体验的影响其实很大。
因为一旦被放到模块里,题目之间就开始有了关系。你会发现自己不是在做一百多道互不相关的题,而是在反复练几类高频能力:
• 某些题训练的是哈希表的互补查找
• 某些题训练的是窗口的扩张和收缩
• 某些题训练的是 DFS/BFS 的建模方式
• 某些题训练的是动态规划里的状态设计
• 某些题训练的是复杂数据结构的组合使用
这时候,复习的重点也变了。你不再只是回忆“上一题答案是什么”,而是开始问自己:“这一类问题的共性是什么?下次换个题面,我还能不能认出来?”
我觉得这一步,才是真正从“刷题”走向“练能力”的分水岭。
真正被训练出来的,是这 5 种底层编程能力
开发者在工作台挑选数据结构模型
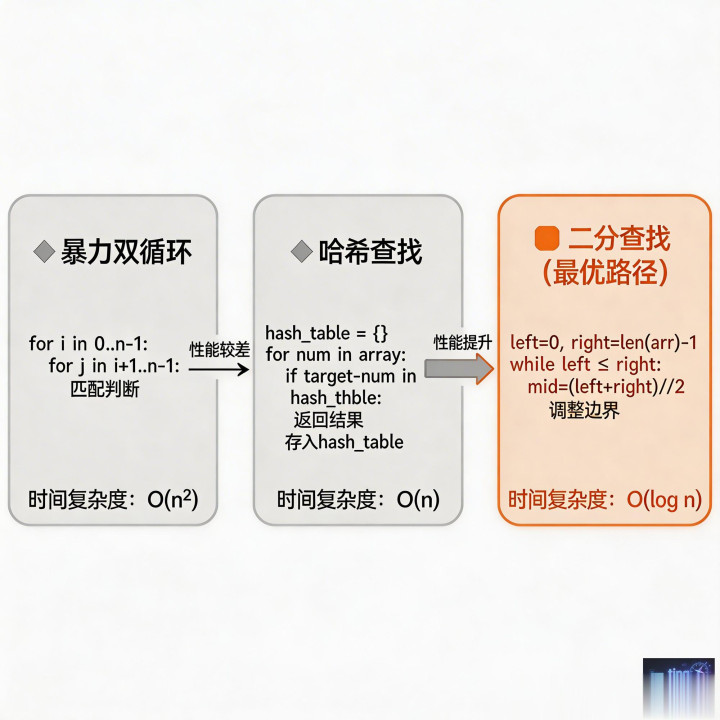
代码优化路径与对应时间复杂度对比图
如果只让我提炼最核心的收获,我会说这 107 道题最后真正逼我练出来的,是下面这 5 种能力。
第一种,是模式识别能力。
真正有效的刷题,不是看到题先想“我做过没有”,而是先判断:这更像哈希表、双指针、滑动窗口,还是 DFS、BFS、DP。两数之和背后是互补查找,最小覆盖子串背后是窗口控制,岛屿数量背后是图搜索,零钱兑换背后是状态设计。你一旦开始用“模式”看题,题和题之间就不再是孤岛。
第二种,是数据结构选择能力。
很多题目的本质,不是算法有多炫,而是你会不会先选对结构。什么时候用 dict 做 O(1) 查找,什么时候用 set 判存在,什么时候用 deque 维护队列,什么时候上堆、链表、Trie,很多时候结构一换,整题复杂度和实现难度就跟着一起变了。
第三种,是复杂度意识。
很多题如果只追求“能跑通”,其实并不难。真正有门槛的是,你能不能在有限时间和空间里,把它写成一个更合理的解。为什么双循环不行,为什么有些题要改成哈希,为什么搜索题必须剪枝,为什么动态规划的状态一旦设计错,整题复杂度就会失控。这些都不是最后补写的“注释”,它本身就是思考的核心。
第四种,是从暴力到最优的推导能力。
这是我后来特别重视的一点。很多人学题解时,上来就背最优解,短期看效率很高,长期反而容易让自己形成错觉,好像答案是凭空跳出来的。真实思考更自然的路径应该是:先接受直觉上的暴力方案,再找性能瓶颈,判断瓶颈出在查找、重复计算、状态维护还是搜索空间,然后再用合适的数据结构和策略去优化。两数之和、零钱兑换、LRU 缓存,这几类题都很适合训练这条链路。
第五种,是结构化表达能力。
做到后面我越来越确定,很多时候真正拉开差距的,已经不是“能不能写出来”,而是“能不能讲清楚为什么这么写”。你能不能把性能瓶颈说清楚,能不能说明为什么选这个结构,能不能讲清时间复杂度和空间复杂度,能不能在题目一变形时快速讲出思路调整。这类能力,对面试有用,对真实开发也一样有用。
很多人刷了不少题,能力却不稳定,常常卡在这两步
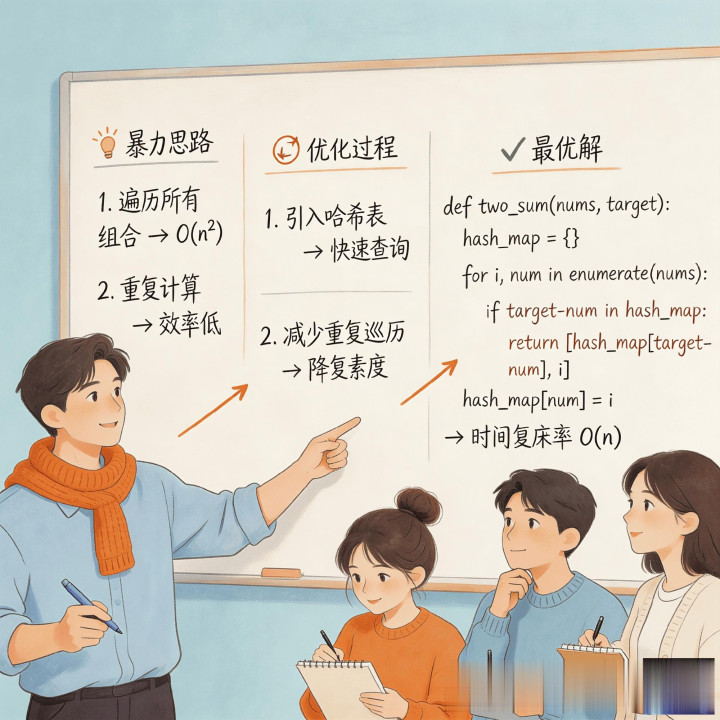
开发者在白板讲解代码思路推导过程
我现在回头看,很多人明明投入了不少时间,能力却一直不够稳定,往往卡在两步。
第一步,是只记答案,不记方法。
这类刷题方式最大的问题,是很容易制造一种“我好像会了”的熟悉感。可熟悉感不等于方法感。你知道某道题该用什么写,并不代表你知道下一道题为什么也该这么写。
第二步,是直接记最优解,跳过中间推导。
这一步的问题比想象中更大。因为真正的编程能力,不是见过答案,而是能不能自己把答案推出来。如果从来不去想暴力解法为什么慢、优化点到底落在哪、为什么这个结构能把复杂度压下来,那很多知识最后就只是“看过”,很难真正迁移。
所以我后来在整理内容时,会尽量把题目描述、边界条件、思路推导、多解法对比、复杂度分析、面试讲法都保留下来。不是为了把文章写长,而是因为这些环节合在一起,才能让一题真正变成一个可复用的训练单元。
如果现在重来一次,我会这样用这 107 题
如果让我用现在的理解,再回头给自己设计一遍刷题路径,我会比以前更强调下面这几个动作:
1. 每做一道题,先判断它属于哪类模式,而不是急着背答案。
2. 写解法前先想数据结构,问自己为什么是它,而不是别的。
3. 一定保留“暴力解法 -> 瓶颈 -> 优化”的推导过程。
4. 做完后强迫自己用口头复盘一遍,练讲解能力。
5. 复习时按模块看,不要按题号零散回看。
我现在再看这 107 道题,已经不会把它简单理解成“面试高频题合集”了。
我更愿意把它看成一套非常高密度的编程思维训练。题目只是入口,真正被训练出来的,是你面对陌生问题时,如何更快建模、选结构、控复杂度、讲方案。
这部分能力,才更接近真正的编程能力。
如果你现在也在刷题,你最卡的部分更像是哪一个:识别模式、选数据结构,还是把思路讲清楚?
如果你也在做这类 AI 工程化实践,完整代码我整理在 GitHub 仓库 tingaicompass/AI-Compass。